W
e know how vital Current RMS is to all our customers and we sincerely apologise for the disruption caused by the downtime we experienced. We appreciate and regret the impact this had on your business and your colleagues and we are truly sorry for this.
In the interests of openness and transparency, we summarise and detail below the circumstances of the outage and its outcome.
Summary
Current-RMS experienced two periods of outage during Monday, June 17th; 04:26 UTC and 15:36 UTC. In each outage period Current RMS was unavailable to the majority of our customers for approximately 3 hours.
The root cause of this outage was an Operating System patch that was applied by Amazon at 00:11 UTC. Unfortunately this patch contained a fault that limited our database server to approximately 50% of its total memory capacity. As we came under load prior to each outage period our database server became memory starved and performance degraded severely resulting in service outages.
The patch was automatically applied by Amazon and we had no prior notice nor choice in the patch being installed on our database servers. We worked closely with Amazon throughout both outages; in the first outage they requested a configuration change that restored service for 6 hours but this did not resolve the fundamental issue and consequently we suffered a second period of outage later that day. Ultimately they provided us with a new “double memory capacity” database server to overcome the effects of their faulty patch. Full service was restored at 18:40 UTC.
Technical Detail
Our database server uses Amazon’s RDS service - this is a fully managed database service where they look after and maintain the complex needs of a large database instance for us. This includes decisions around when and what patches are applied to the operating system and server architecture. We have no control over this part of their service other than to configure what time of day these changes can be made.
Our primary database server runs PostgreSQL on an 8 CPU, 32G RAM RDS instance. We have 1.5T of provisioned storage providing us with 4500 IOPS (input/output operations per second) capacity that can burst to almost double that level.
We also make use of Amazon’s “Multi-AZ Failover” service - this provides an exact synchronised replica of our primary database server in another availability zone that will automatically kick-in should a serious fault occur. Failover typically takes less than 60 seconds.
During normal operation free memory on our database instance does not fall below 25%, total free storage is over 1T, IOPS rarely exceed 2000 and CPU usage never exceeds 50%. Our database server therefore has significant spare resources, never exceeded safe limits, and has an identical twin to failover to should anything serious occur. It has run in this particular configuration for 18 months without incident and no incidents in configurations prior to that.
The “Patch”
Amazon’s patch was intended to assist the underlying operating system the database server runs on, ensuring a quantity of system memory was held back for it to perform optimally. All operating systems need memory to operate correctly so on the face of it this patch was well intended.
Unfortunately the limits, or the way the patch calculated the amount of memory to reserve proved to be faulty resulting in far too much memory being held back from the database server. During the outages we were seeing anywhere from 40% to 50% of total capacity being held back.
As stated above, we typically use around 75% of system memory, therefore with this patch holding back 40-50% we fell significantly short of the system memory we needed to operate as load grew through the morning period. Once we hit this new artificial limit our server was forced to use “swap” memory to fill the gap.
Swap memory is a method to release system memory when it is under pressure (e,g. low free memory). It moves blocks of system memory to and from permanent storage, thereby freeing up memory for immediate tasks. The processing and swapping of memory is extremely slow (when compared to just using system memory) and this resulted in performance degradation that got significantly worse as more and more swap memory needed to be used.
The patch was applied to both our primary and secondary (replica) database servers at the same time, therefore both were similarly affected and we could not implement our failover recovery procedures to restore service quickly.
Impact
As load increases our memory requirements also increase, with the patch limiting access to system memory and the need to start using swap memory, database queries that would typically execute in a few milliseconds were taking whole minutes. This resulted in our application servers, that process your page requests, getting backlogged and then ultimately overwhelmed and automatically taken out of service to recover. A cascade effect meant all servers were eventually taken out of service as they became overloaded resulting in an outage.
The first outage began at 04:26 UTC - our monitoring service alerted on-call engineers to the issue immediately and we began investigating. Within 15 minutes of the alert service had been restored and all seemed to be well. Unfortunately 40 minutes later another outage occurred at 05:19 UTC. Further investigation was carried out and during that time it was identified that the database server was the core problem due to it performing well below expected levels. We began assessing and implementing our usual recovery protocols, however, whilst these initially restored service it soon failed again, leading to another outage at 05:36 UTC. Another recovery attempt was made and service was restored only for it to fail once again at 05:48 UTC. We could see nothing wrong with our infrastructure other than the unusually poor performance of our database server, all other measures and monitoring were normal.
Having worked through our normal recovery procedures three times and still facing issues, we contacted Amazon through our premium support package at 05:50 UTC.
After lengthy and detailed investigation by both ourselves and Amazon (who were as baffled as we were as to why the problem was occurring), we noticed that our database server had unusually begun to use swap memory at around 00:21 UTC. Historically our database server has never used swap and it wasn’t something we actively monitored - we do monitor free memory and in usual operation of a server you would not begin to use meaningful amounts of swap unless free memory becomes low. Amazon support then brought to our attention that an operating system patch had been applied at 00:11 UTC - just 10 minutes prior to when our server started using swap memory.
Armed with this information, further investigations were carried out by Amazon. Following this we were told that the patch was now suspected as being the root cause and that we needed to make a small configuration change to our database server to compensate for its behaviour. We made this change at 08:20 UTC and rebooted our database server to implement it. Service was restored at 08:34 UTC.
We then ran for 6 hours without any issue until 14:35 UTC when swap usage started to climb before spiraling out of control. Here’s a chart of swap usage covering the period of the two outages: -
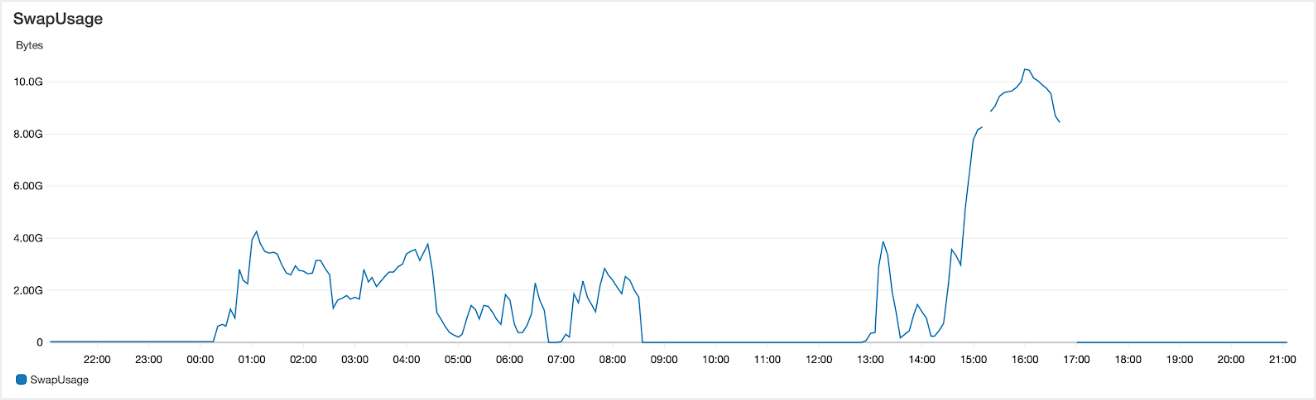
The second period of outage used significantly higher amounts of swap and caused a very sudden period of outage at 14:35 UTC. On this graph you can also see that prior to 00:11 UTC (when the patch was applied) we used zero swap.
We immediately consulted with Amazon who began a high priority investigation. Whilst the patch was still prime suspect, Amazon were initially unsure of why the configuration change did not resolve the issue and pursued this as their initial line of enquiry. At 16:03 UTC they told us that they now understood the patch’s memory limiting behaviour to be faulty and that we needed to upgrade our database instance to work around the issue.
We began the upgrade process immediately, however, because the server was now running so slowly, it took far longer than expected for the upgrade to complete. Frustratingly, we had to wait this out to ensure data integrity was maintained. The upgrade finally completed at 17:25 UTC and after carrying out system and data checks, we restored full service at 17:40 UTC.
Resolution
Once the patch was identified as the root cause and that its overly aggressive memory limiting behaviour was faulty, we could plan a more permanent resolution. As the patch was limiting us to 50% of total memory capacity, the straightforward answer was to move to a database server instance that had double the memory.
Outcome
... the OS patch was aimed to restrict the usable memory for the database engine and to avoid potential outages.
Amazon tech support 17:01 UTC
Whilst the patch was well intended, its actual effect was to starve the database engine of memory and cause outages - the very thing it was supposed to prevent. Amazon have assured me they QA and test all patches before rolling out to production instances, and are currently investigating how this one slipped through the net and caused the issues it did. Amazon have also stated to us that we were not the only ones affected by this faulty patch.
What could we have done differently to either prevent the outage or limit its duration?
- We could have engaged with Amazon support earlier during the first outage. With the benefit of hindsight, our repeated attempts to follow our recovery processes were unnecessary and simply delayed matters.
- We should have made more regular status page updates and set the status page to “System Down” rather than “Degraded Service” as we did during the first outage. Clearly we were heavily occupied with resolving the issue and lost sight of these updates - in the future we will communicate more regularly so everyone stays fully informed.
- Monitoring swap usage could have led us to the root cause earlier and we now have that in place.
The fundamental issue was high swap usage caused by the faulty patch. Historically we have never used swap (in more than 5 years) and we closely monitor and have alarms configured for when free memory falls to lower than expected levels (when you would expect swap to be used), however, the unique and unforeseeable behaviour of this patch meant that swap was used even when free memory was high.
We have held initial conversations with Amazon who have apologised for the impact their faulty patch had, and they are now performing a detailed post-mortem on the impact it has had on users of their database service. Clearly we will be wanting to see action from Amazon to ensure that this sort of mistake cannot be made again in the future, and we will also be working with them to explore options around changes to their service to restore operations much faster should anything like this happen again.
Once again, I would like to offer my sincere apologies for the disruption in service and my heartfelt thanks and appreciation to all those customers who contacted us with messages of support both during the outage and afterwards.
Chris Branson
CEO
June 24th, 2019